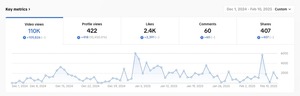
~hackernoon | Bookmarks (2034)
-
Some of the Most Popular Dark Matter Candidates: Looking Into the Standard Model
These are DM candidates, which were produced thermally in the early universe when it was in...
-
Vibe Coding - A New System of the World
Software engineer and software entrepreneur, Woody Hayday, says AI will soon do a better job than...
-
Security's Moving Parts 01: Linux Access Control Mechanisms
Nikolai Khechumov: Security's Moving Parts is a series of articles on security in software and hardware....
-
Social Recognition: A Must for Developers in Today's World
The role of a developer has changed as the world has changed. It's no longer enough...
-
The Myth of Connectivity: Uncovering the Global Blueprint of Digital Deception
This paper is presented as an analysis of transnational misinformation diffusion, showing that cultural, thematic, and...
-
fmt.Sprintf: Looks Simple But Will Burn A Hole in Your Pocket
This article explores various methods for string concatenation and conversion in Go. It demonstrates that for...
-
Graphing the Gossip: Unraveling Social Media Conspiracies
This paper is presented as an ERGM-based analysis of transnational factors shaping tie formation in Facebook...
-
To PR or Not to PR, That Is the Question
Many founders and C-levels confuse marketing and advertising with public relations. PR focuses on maintaining a...
-
Tariffs or No Tariffs, Smart Dealers Are Betting on Used Vehicles - And You Should Too
Dealers who wait for a final ruling on March 6 will already be behind. Smart operators...
-
AI Agents: How They're Getting Ready to Blow Up the Business Process Layer
Understand why integrating AI agents into enterprise architectures marks a transformative leap in the way organizations...
-
Learn to Create an Algorithm That Can Predict User Behaviors Using AI
Link prediction aims to predict the likelihood of a future or missing connection between nodes in...
-
The Psychology Behind Successful Pair Programming
This research highlights the psychological benefits of pair programming, emphasizing motivation, social skills, and role dynamics....
-
What Science Says About Learning to Code in Pairs
This study examines the psychological effects of pair programming in education, highlighting motivation, social skills, role...
-
How Pair Programming Affects Student Motivation and Learning
Quantitative analysis confirms that pair programming roles significantly impact motivation, with pilots and navigators more engaged...
-
Measuring Intrinsic Motivation in Pair Programming
This study measures intrinsic motivation in pair programming using self-report surveys and the Big Five personality...
-
Does Programming with a Partner Make Learning Easier?
This study investigates pair programming’s impact on student motivation in software engineering courses. Conducted over four...
-
Pair Programming: The Buddy System, But With Fewer Bugs (Hopefully)
This study examines the psychology of pair programming, analyzing intrinsic motivation in pilot, navigator, and solo...
-
The HackerNoon Newsletter: The First Provable AI-Proof Game: Introducing Butterfly Wings 4 (2/10/2025)
How are you, hacker? 🪐 What’s happening in tech today, February 10, 2025? The HackerNoon Newsletter...
-
The Importance of Liquidity: How It Impacts Crypto Trading
Liquidity is essential for crypto trading, affecting price stability, transaction speed, and slippage. High liquidity minimizes...
-
Meet BNB Chain: HackerNoon Company of the Week
HackerNoon is proud to shine a spotlight on BNB Chain, a decentralized blockchain ecosystem developed by...
-
HackerNoon Decoded 2024: Celebrating Our Writing Community!
Welcome to HackerNoon Decoded—the ultimate recap of the Writing stories, writers, and trends that defined 2024!...
-
Do You Need to Give Up jQuery for React?
As developers, we see that every software technology has its pros and cons. It’s same for...
-
Holonym Acquires Gitcoin Passport to Build the World’s Largest Proof of Humanity Network
Holonym Foundation has acquired Gitcoin Passport, a widely adopted digital identity verification tool. The acquisition aims...
-
AI Meets Beat Poetry: Allen Ginsberg’s HOWL Reimagined Through Generative Art on Tezos
HOWL.camera is a revolutionary AI-powered art experience transforming Allen Ginsberg’s iconic poem HOWL into dynamic generative...